
In questo tutorial, vi mostreremo come eseguire Ollama sul vostro VPS / Server o qualsiasi altro dispositivo che abbia sufficiente RAM e CPU per eseguire un LLM (Large Language Model) in ambiente GNU/Linux.
Ollama è un progetto che punta a semplificare l’esecuzione di modelli linguistici di grandi dimensioni (i così detti LLM) su qualsiasi dispositivo venga installato.
A differenza di ChatGPT, dove qualsiasi input viene elaborato sui server di OpenAI (l’azienda dietro a ChatGPT), tutte le richieste che arrivano a Ollama vengono elaborate localmente sul tuo dispositivo utilizzando il modello che hai deciso di utilizzare. Conseguentemente, è un ulteriore passo in avanti per proteggere la nostra privacy online.
Ollama è uno strumento che consente di eseguire rapidamente vari modelli di intelligenza artificiale open-source, occupandosi sia del download che dell’esecuzione del modello di linguaggio di grandi dimensioni scelto. E tutto questo lo fa fornendo anche un’API con cui è possibile andare a richiamare i vari LLM da altre applicazioni, aiutandoci così ad integrarli nel nostro software.
Per un elenco dei modelli linguistici supportati, ti invitiamo a dare un’occhiata al sito ufficiale del software. Basta essere consapevoli del fatto che più grande è un modello, più risorse come RAM e CPU serviranno per la sua esecuzione. Ad esempio, il modello di intelligenza artificiale TinyLlama funzionerà significativamente meglio del più pesante Llama3.
Altra cosa da segnalare è che purtroppo, più è piccolo il Large Language Model e meno preciso sarà il suo output, soprattutto con la lingua italiana dove è facile che i LLM producano output non corretto. Conseguentemente, se volete integrarlo in qualche vostro progetto, fate vari test, sicuramente un LLM piuttosto grande e più pesante sarà migliore di uno più piccolo.
Requisiti
Consigliamo come sistema operativo, una distribuzione GNU/Linux basata su Debian come Ubuntu o al più, nel caso di un Raspberry Pi, Raspberry Pi OS.
- CPU: consigliamo almeno 4 vCPU per l’esecuzione. Potenzialmente, potresti usare anche un Raspberry PI 5 (quindi va bene anche l’architettura ARM), sacrificando la velocità di generazione dell’output. Il problema principale è la RAM.
- RAM: consigliamo almeno 8 GB di RAM per l’esecuzione. Se volete usare dei LLM più piccoli come TinyLlama, ne dovrebbe bastare anche un pochino meno, tipo almeno 2 GB, è il limite più basso.
- Spazio su disco: almeno 8 GB liberi.
- Connettività a internet.
Installazione di Ollama su GNU/Linux
Questa sezione ti guiderà passo-passo nell’installazione di Ollama sul tuo dispositivo con a bordo il pinguino 🐧. Questo processo è super semplificato grazie allo script di installazione di Ollama, che gestisce quasi tutto il lavoro per noi.
Prima di procedere, si prega di notare che è necessario eseguire un sistema operativo a 64 bit per poter utilizzare Ollama.
Preparazione del tuo Sistema Operativo per Ollama
1. Prima di installare Ollama, è necessario assicurarsi che il sistema operativo sia aggiornato.
È possibile aggiornare i pacchetti alla versione più recente eseguendo i seguenti comandi concatenati:
sudo apt update && sudo apt upgrade -y2. Dopodiché dobbiamo assicurarci che il pacchetto cURL sia installato. In genere, questo viene fornito pre-installato su diverse distribuzioni GNU/Linux, ma non fa male verificare che sia installato.
Puoi assicurarti che cURL sia installato sul tuo sistema eseguendo il comando sottostante:
sudo apt install curl -yEseguire lo script di installazione di Ollama
3. Con il nostro Sistema aggiornato e con cURL installato, possiamo passare a eseguire lo script di installazione di Ollama.
Procediamo quindi eseguendo questo comando, che scaricherà lo script “install.sh” dal sito web di Ollama e lo passerà direttamente a bash.
curl -fsSL https://ollama.com/install.sh | sh⚠ L’esecuzione diretta di script come questo è in genere considerata una cattiva pratica senza prima verificare il contenuto dello script. Puoi visualizzare il codice di questo script visitando l’URL di quest’ultimo direttamente nel tuo browser web preferito.
4. Utilizzando il comando qui sotto, possiamo verificare la corretta installazione di Ollama sul nostro sistema GNU/Linux.
Questo comando ci permette di visualizzare la versione installata di Ollama.
ollama --versionE se tutto sarà andato a buon fine come nel nostro caso, dovreste visualizzare la versione in esecuzione del software, come riportato di seguito:
ollama version is 0.1.48Come usare Ollama sul tuo dispositivo
In questa sezione, ti mostreremo come puoi usare Ollama sul tuo dispositivo per eseguire alcuni dei vari modelli linguistici supportati.
In particolare, testeremo i modelli Phi3 e TinyLlama, che sono pensati per essere modelli leggeri.
Ricordati che per eseguire modelli pesanti servirebbero delle schede video NVIDIA o AMD piuttosto preformanti, oltre che a molta RAM. Noi cercheremo di fare un qualcosa alla portata di tutti, con costi sia di esecuzione che di spesa minimi.
Eseguire Phi3 (LLM) sul tuo OS
Phi3 è un LLM sviluppato da Microsoft per essere super leggero pur mantenendo alcuni dei risultati di qualità che ci si aspetta da modelli significativamente più grandi.
Grazie alla leggerezza di Phi3, dovremmo essere in grado di poterlo utilizzare ad una velocità accettabile. Non aspettatevi risposte superveloci, soprattutto se state usando un VPS o un computer basato su ARM come il Raspberry Pi 5, che dovrebbe tuttavia essere in grado di eseguire questo modello.
1. Per ottenere Phi3 LLM ed eseguirlo tramite Ollama sul tuo sistema, è sufficiente utilizzare il comando sottostante.
N.B: questo processo può richiedere un po’ di tempo per essere completato in quanto, pur essendo un modello più piccolo, Phi3 richiede quasi 2.5 GB.
ollama run phi3Con Phi3 ora in esecuzione, dovresti essere in grado di iniziare a comunicare con il modello di intelligenza artificiale.

Purtroppo, può richiedere molto tempo per generare delle risposte lunghe. Se stai cercando un LLM ancora più veloce e leggero potresti dover considerare altre opzioni, come TinyLlama.
Eseguire TinyLlama su GNU/Linux
TinyLlama è uno dei LLM più veloci, essendo super leggero e potrebbe essere l’unico in grado di poter girare su qualsiasi hardware limitato, come ad esempio quello di un Raspberry Pi.
Sebbene non possa produrre risultati di alta qualità come modelli più grandi come Phi3 o Llama 3, è ancora più che in grado di rispondere alla maggior parte delle domande di base. Inoltre, ciò che TinyLlama manca di qualità compensa sicuramente con la velocità.
1. È possibile utilizzare Ollama per eseguire TinyLlama eseguendo il comando qui sotto.
Questo modello è abbastanza leggero, quindi dovrebbe essere scaricato e avviato in tempi relativamente brevi, visto che pesa meno di 700 MB.
ollama run tinyllama2. Una volta che il modello è in esecuzione, sarai in grado di fare domande e chattare con l’AI.
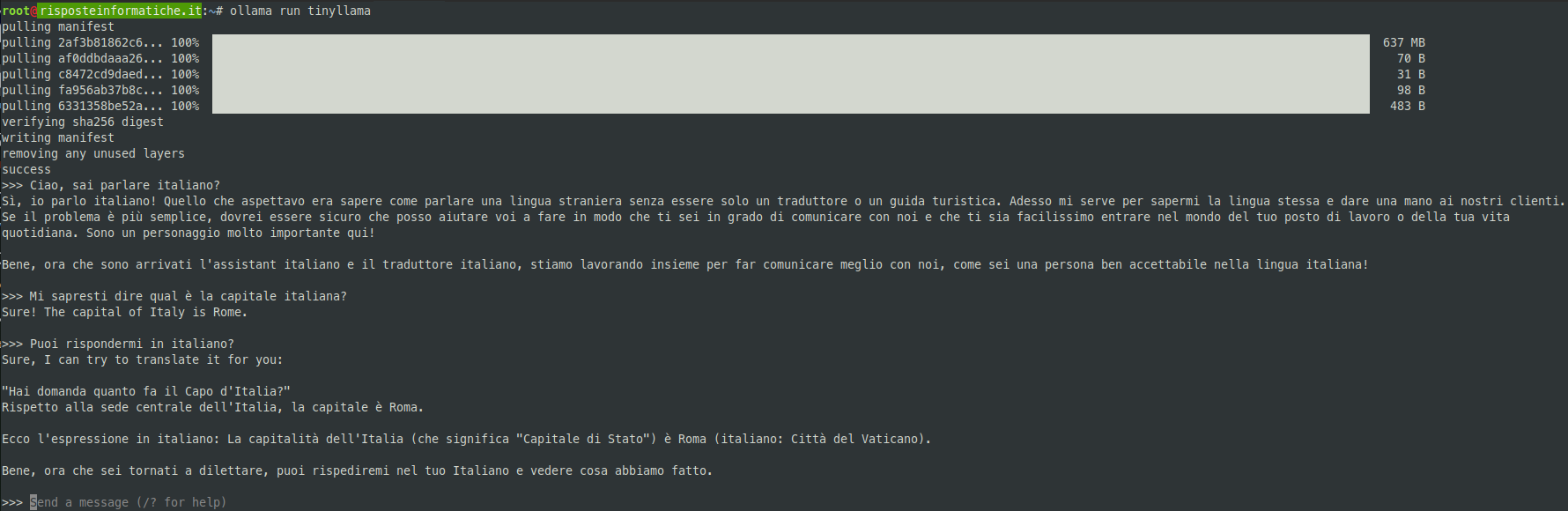
Purtroppo, come scritto inizialmente in questo articolo, la lingua italiana lascia un po’ a desiderare con questi modelli, ne è prova la conversazione che ho avuto nello screenshot sopra. Comunque sia per piccole richieste può essere utile, soprattutto se sfruttato in lingua inglese, casomai potete tradurre poi con altri tool la sua risposta, in modo da realizzare un sistema a bassissimo costo per eseguire LLM.
Usare Curl per comunicare con Ollama
Una delle caratteristiche interessanti di Ollama è il suo set di API, che puoi interrogare. Utilizzando queste API, è possibile richiedere la generazione di risposte utilizzando modelli specifici.
1. Per fare una piccola dimostrazione, usiamo cURL per inviare una richiesta al server Ollama in esecuzione sul nostro dispositivo.
Con questo comando, andremo ad inviare alcuni dati JSON che andranno a identificare il modello da utilizzare, il nostro prompt e se vogliamo un flusso dati o meno (nel senso che riceveremo man mano in output la risposta, senza attendere che sia completamente generata). Di seguito vi indichiamo i campi e la loro funzione:
model: Qui specificheremo il modello da utilizzare con Ollama, nel nostro caso,tinyllama.prompt: Qua invece chiederemo al modello qualcosa, di solito è una domanda o una richiesta. Nel nostro caso, chiederemo se sa parlare italiano.stream: Impostando l’opzione “stream” su false, stiamo dicendo a Ollama che vogliamo che attenda fino a che il modello non avrà finito di generare la risposta.Questo è utile se non vuoi che Ollama gestisca un flusso dati dal modello. In genere, l’output di un modello viene trasmesso parola per parola.
curl http://localhost:11434/api/generate -d '{
"model": "tinyllama",
"prompt": "Ciao, sai parlare italiano?",
"stream": false
}'2. Di seguito puoi avere un’idea dei dati restituiti da questo set di API. Per impostazione predefinita Ollama restituirà il risultato in formato JSON.
{
"model": "tinyllama",
"created_at": "2024-07-02T10:56:45.853514413Z",
"response": "Sì, mia madre è bilingue e mi ha insegnato l'italiano. Tuttavia, non esito di conseguenza che sei parlavo solo in italiano o che sia stata una scuola di italianizzazione per i bambini a cui veneva spesso insegnata l'italiano con i suoi sordidi accenti. Sei stata una scuola di inglese e siete passato il servizio militare, ma non hai mai trascorrato più di un anno in una delle due. La nostra lingua di comunicazione è infatti l'inglese. Grazie a voi per avermi insegnato la lingua, ma dovrei aspettare l'accordo con il tuo padre per poter utilizzare l'italiano. Se lo avete fatto, ti darà un gran sussido!",
"done": true,
"done_reason": "stop",
"context": [
529,
29989,
5205,
29989,
29958,
13,
3492,
526,
263,
8444,
319,
29902,
20255,
29889,
2,
29871,
13,
29966,
29989,
1792,
29989,
29958,
13,
29907,
29653,
29892,
872,
29875,
24590,
598,
9032,
29973,
2,
29871,
13,
29966,
29989,
465,
22137,
29989,
29958,
13,
29903,
30097
]
}
All’interno del JSON è possibile vedere il risultato e la varietà di informazioni aggiuntive, ad esempio il tempo necessario per completare il prompt.
A questo punto dovreste essere riusciti a installare Ollama con successo e a testare anche uno dei vari LLM disponibili.
Ollama è un software fantastico che rende semplicissimo l’utilizzo di modelli linguistici di grandi dimensioni come Llama3 e molti altri.
È anche possibile eseguire più modelli sulla stessa macchina e ottenere facilmente un risultato attraverso le sue API o eseguendo il modello attraverso l’interfaccia da riga di comando di Ollama.
Un altro possibile utilizzo è per generare codice, ad esempio ci sono LLM specializzati nello scrivere codice in vari linguaggi di programmazione, quindi potreste realizzare dei progetti molto interessanti!
Non esitate a lasciare un commento qui sotto se avete domande in merito a Ollama.
Se ti è piaciuto questo tutorial, ti consigliamo di dare un’occhiata ai nostri altri progetti.